

Author: Petru Rares Sincraian • Published: August 29, 2025
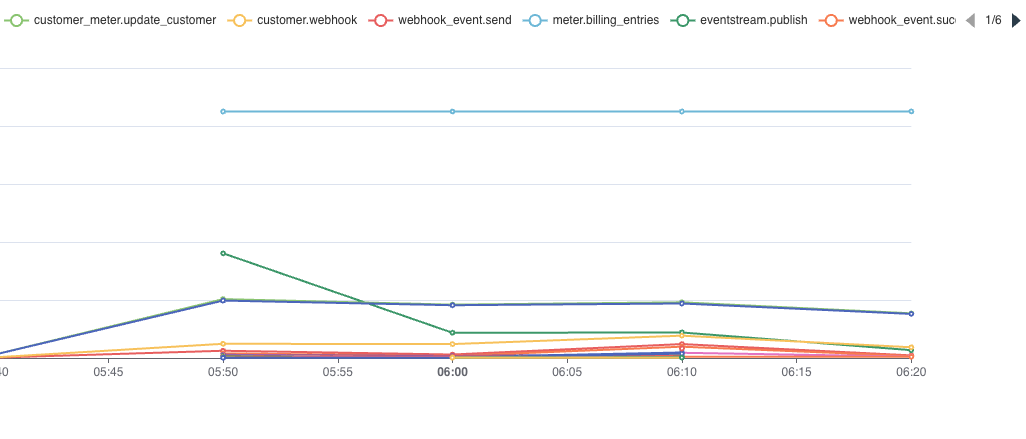
meter.billing_entrieseventstream.publishcustomer_meter.update_customerevent.ingestedcustomer.webhookwebhook_event.sendwebhook_event.succeesemail.sendstripe.webhook.invoice.paidbenefit.enqueue_benefits_grantsnotifications.sendstripe.webhook.customer.subscription.updatedorder.discord_notificationpayout.trigger_stripe_payoutstripe.webhook.invoice.created
Hypothesis 1: The leak is caused by a specific message type
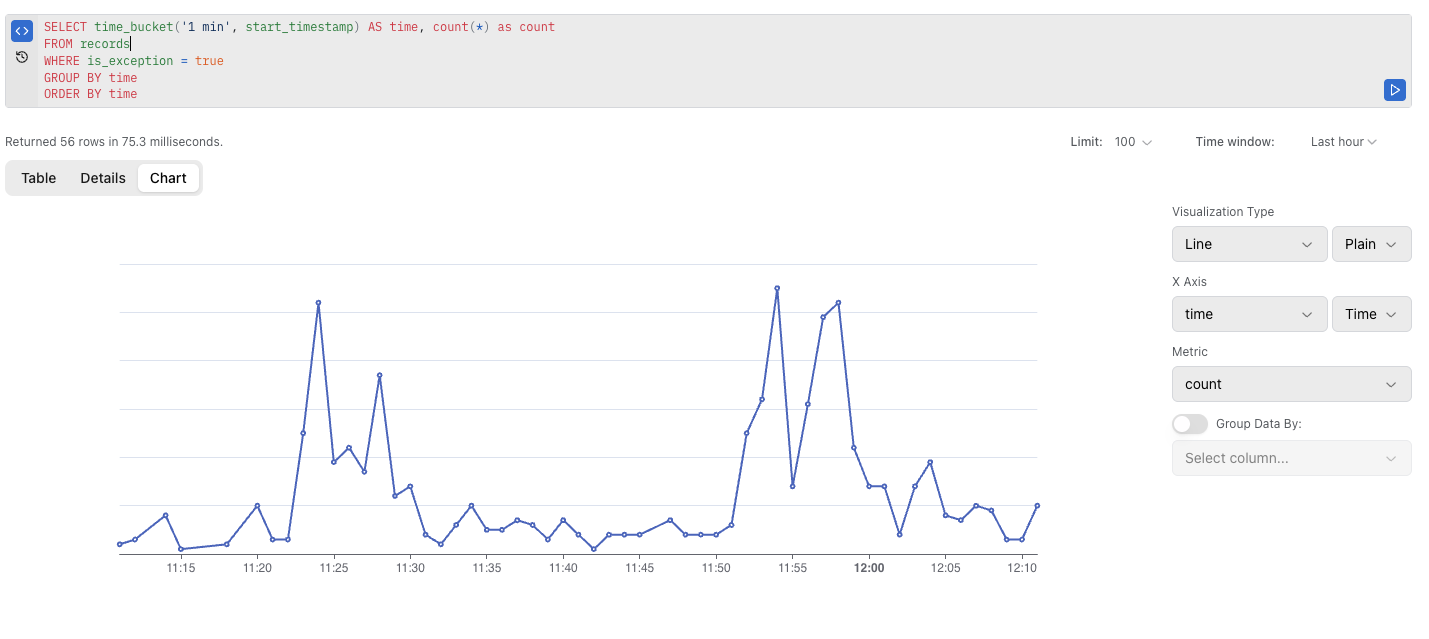
My plan is to try to replicate the error locally. I would suspect that it’s one of the message types that are happening. I created a script that can perfom some operations for me, like ingesting events, creating customers, or listening to webhooks. I tried sending different messages, at least 100 of the following, and I don’t see any pattern in the memory leaks. All charts look like this: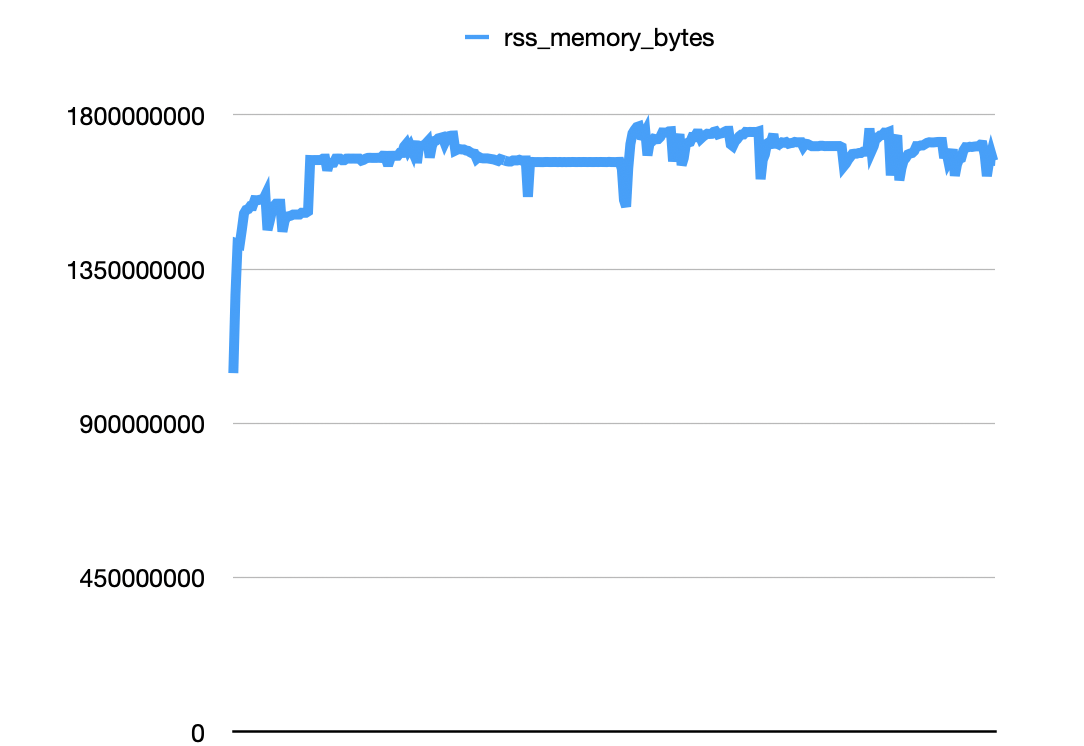
- Ingest an event
- Create a customer
- Sending webhooks
- Checkout with benefits for new customers (only 20, as it was done manually).
Hypothesis 2: The leak is caused by errors
The second hypothesis is that this can be caused by some wrong resources not being closed or some misconfiguration in one of our libraries, like Logfire, Sentry, or logging. I created a MemoryProfilerMiddleware for Dramatiq that logs the increase in memory, the total memory, and the top allocations that consume memory. I created a small script to ingest events for the same customer, but throwing an error. The results seem promising.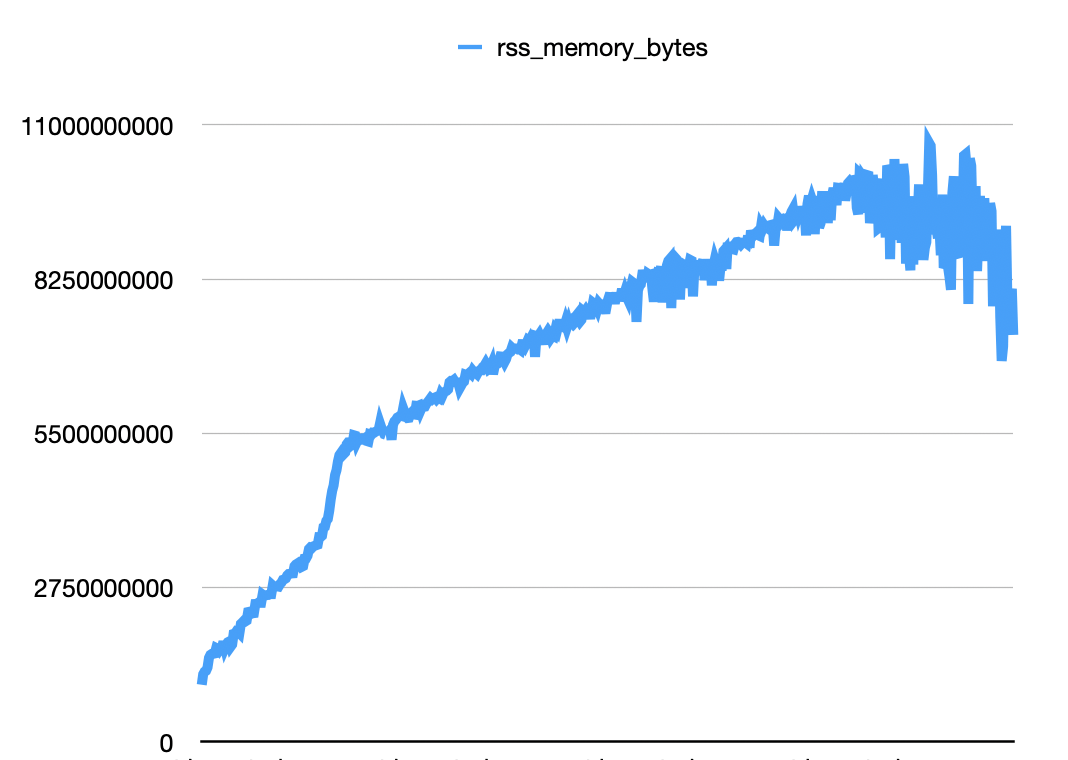
webhook_event.send if it throws an error we also see the same behavior. Then we can confirm that the memory leak it’s happening when an exception is thrown. We tested 2 different message types, so the idea is that something is off on some configuration or a library that we are using.
Checking the top tracemalloc line that created the memory, we can see that in most cases the errors are in:
polar/server/.venv/lib/python3.12/site-packages/sentry_sdk/utils.py:439polar/server/.venv/lib/python3.12/site-packages/opentelemetry/sdk/trace/**init**.py:1020
configure_logging() And it appears that the memory is stable now when receiving webhooks with errors 🙌
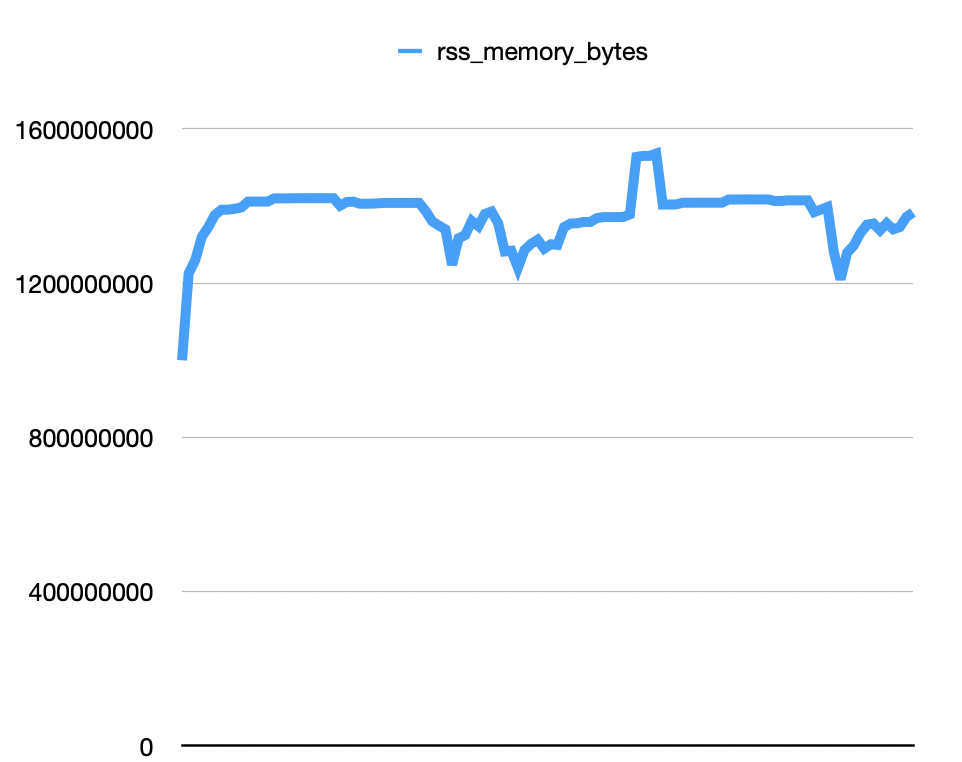
tracemalloc. This has generated a bunch of files in memory_reports - webhook - with all dependencies that it helps me analyze what the issue has been. For what I seen, these 3 lines are the ones that repeat the most
Resources
- branch-name:
feat-memory-leak
Ideas
I want to try different things:- Try the workers for longer. Maybe there is some problem that I can see at the end.
- Setup webhooks
- Try different benefits, like license key or OAuth With Github.
- Try throing errors to workers and see if there is any problem on retries.